An Oracle database server can be configured to run either a dedicated or shared server architecture. This decision determines how the listener processes requests and how server processes work for an Oracle instance. Server processes are the interface between the Oracle database server and user processes, the latter of which must go through a server process that handles the database communication between the user process and the database. Server processes can
-
Process database requests, access data, and return the results.
-
Perform data translations and conversions between the application and database server environments.
-
Protect the database server from illegal operations by the user processes. A server process accesses Oracle database and memory structures on behalf of the user process. This separates user process activity from direct access to Oracle’s internal memory.
Dedicated Server
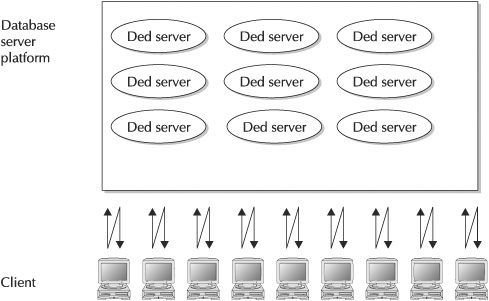
A dedicated server environment uses a “dedicated” server process for each user process. The benefit of this is that each user process has a dedicated server process to handle all of its database requests. If there are a hundred separate sessions, there will be a hundred dedicated server processes running on the same platform as the database server.
The problem is that each dedicated server process is often idle a large percentage of the time. This takes up a lot of operating system resources for server processes that are sitting idle and creates issues when large numbers of users are accessing a system. Oracle databases that allow access from the Internet can have tremendous spikes of activity that generate a large number of dedicated server processes. The dedicated server architecture also does not support FTP, HTTP, or WebDAV clients.
Figure 1 illustrates the way that dedicated server processes run on the database server platform. A dedicated server process will be run for each user session.
Figure 1. The dedicated server architecture
Shared Server
A shared server architecture offers increased scalability for a large number of users. This is possible because a single server process can be “shared” among a number of user processes, allowing a single server process to be able to support a large number of user processes. If there are 100 separate sessions, there may in turn be 20 shared server processes supporting them. Having a small pool of server processes that can support a large number of sessions increases scalability. This shared server architecture is much more scalable than a dedicated architecture as the number of users for a system increase. The shared server process can also handle large spikes of user activity much better than a dedicated server process configuration.
When a user request arrives, the listener will route the request to a dispatcher, which then processes and routes the request to a common queue. From a pool of shared server processes, an idle shared server will see if there is work in the common queue. Requests are processed on a first-in first-out basis. The shared server then processes the request and puts the results in a response queue (each dispatcher has one) that a dispatcher can return to the user process. Afterward, the dispatcher returns the results from its response queue to the appropriate user process.
A dispatcher supports multiple connections with virtual circuits, which are sections of shared memory that contain the information necessary for client communication. The dispatcher puts the virtual circuit on the common (request) queue accessed by the server process.
There are some administration operations that cannot be performed through a dispatcher, however. To perform these restricted administration operations in a shared server environment, the DBA needs to connect with a dedicated server process instead of a dispatcher process. The restricted operation needs a connect descriptor with a setting of SERVER=DEDICATED, defined in the CONNECT_DATA section of the tnsnames.ora file: (CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = MMDEV1)). Restricted operations include the following:
-
Starting up an instance
-
Shutting down an instance
-
Media recovery
As Figure 2 shows, a shared server process can support multiple user sessions.
Figure 2. The shared server architecture
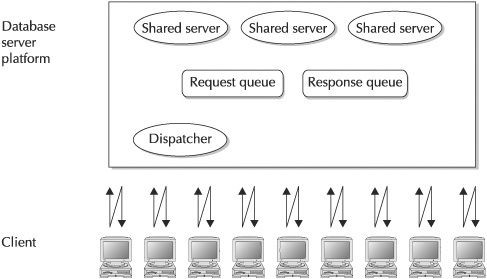
Table 1 illustrates the initialization parameters that are used to configure the shared server architecture. Possible values for these parameters are dependent on the level of user activity and the types of operations the server processes are executing.
| Oracle Initialization Parameter | Definition |
|---|---|
| DISPATCHERS | This defines the number of dispatcher processes to start in a shared server architecture. The number of dispatchers can be dynamically added or reduced. There must be at least one dispatcher for each network protocol. Additional dispatchers can be defined based upon the workload. |
| MAX_DISPATCHERS | This defines the maximum number of dispatchers. This is not a fixed limit. In this release, this value can be dynamically exceeded at runtime. |
| SHARED_SERVERS | This defines the number of shared servers to invoke on database startup in a shared server architecture. |
| MAX_SHARED_SERVERS | This defines the maximum number of shared server processes. |
| SESSIONS | This defines the maximum number of sessions that can be active in a system. |
| SHARED_SERVER__SESSIONS | This defines the maximum number of shared server sessions that can be started in a system. It also allows dedicated sessions to be reserved in a shared server environment. Sessions started above this limit will use dedicated server processes. |
| CIRCUITS | This defines the maximum number of virtual circuits. |
| LARGE_POOL_SIZE | This defines the size of the large pool area in the SGA. If a large pool exists, the session information will be stored in the large pool, not the shared pool area. |
Oracle recommends starting with one shared server process for every ten connections. It then automatically increases the number of shared servers based upon the workload up to the MAX_SHARED_SERVERS that are defined. The PMON process is responsible for adding and removing shared servers; the number of shared servers will never drop below the value contained in the SHARED_SERVERS parameter. You should also note that the parameters that control the minimum and maximum number of these shared servers can be set dynamically; therefore you can always ensure that you can react quickly to shared server issues.
Set Dispatchers
To set the number of dispatchers, determine the maximum number of concurrent sessions and divide this by the number of connections per dispatcher. Then, dependent upon the level of activity, the number of dispatchers may need to be increased or decreased. A single dispatcher can handle a large number of shared server processes, but the number of dispatchers per shared server is dependent upon the activity of the shared server processes.
One of the following attributes—PROTOCOL, ADDRESS, or DESCRIPTION—can be set with dispatchers. PROTOCOL defines the network protocol to use, ADDRESS defines the network protocol address on which the dispatchers listen, and DESCRIPTION is the network description. Default values are used if the attributes are not defined, and additional network options can be defined if the ADDRESS or DESCRIPTION attribute is set.
Additional attributes that can be set with ADDRESS or DESCRIPTION include the following:
-
SESSIONS This defines the maximum number of network sessions per dispatcher.
-
CONNECTIONS This defines the maximum number of network connections per dispatcher.
-
TICKS This defines the length of a network tick (seconds). A tick defines the length of time for a message to get from the client to the database server or from the database server to the client.
-
POOL This defines the timeout in ticks for incoming (IN=15) and outgoing (OUT=20) connections, and whether connection pooling is enabled. The number of ticks multiplied by the POOL value determines the total connection pool timeout.
-
MULTIPLEX This defines if multiplexing with the Connection Manager is set for incoming and outgoing connections. Multiplexing allows multiple sessions to transport over a single network connection. This is used to increase the network capacity for a large number of sessions.
-
LISTENER This defines the network name of an address for the listener.
-
SERVICE This defines the server names that dispatchers determine with the listeners.
-
INDEX This defines which dispatcher should be modified.
In your init.ora file, you will define the dispatchers. The following are examples of different types of entries that will typically be created to support shared servers.
Define the number of dispatchers to start:
DISPATCHERS='(PROTOCOL=TCP)(DISPATCHERS=5)'
Define a dispatcher to start on a specific port:
DISPATCHERS='(ADDRESS=(PROTOCOL=TCP)(DISPATCHERS=5))'
Define a dispatcher with more options:
DISPATCHERS="(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)
(HOST=eclipse)(PORT=1521)(QUEUESIZE=20)))
(DISPATCHERS=2)
(SERVICE = customer.us.beginner.com)
(SESSIONS=2000)
(CONNECTIONS = 2000)
(MULTIPLEX = ON)
(POOL = ON)
(TICK = 5)"
As you can see, there are numerous options that may be used, depending on the configuration methods that you select when configuring the dispatcher.
Views to Monitor the Shared Server
The following views can be used to monitor the load on the dispatchers:
-
V$DISPATCHER
-
V$DISPATCHER_RATE
-
V$QUEUE
-
V$DISPATCHER_CONFIG
The following views can be used to monitor the load on the shared servers:
-
V$SHARED_SERVER
-
V$SHARED_SERVER_MONITOR
-
V$QUEUE
The V$CIRCUIT view can be used to monitor virtual circuits.
The following views can be used to monitor the SGA memory associated with the shared server environment:
-
V$SGA
-
V$SGASTAT
-
V$SHARED_POOL_RESERVED
These views provide you with the ability to monitor your database and the activity related to your shared servers and database. We encourage you to take a look at the data in these tables before and after you implement shared servers, to see how they change your database and how it functions.
