1. Troubleshooting Crawl Errors
All too often, users complain about missing content in search engines. Either impatient users expect their content to appear immediately or some crawling issue causes the content to be skipped during indexing. Undefined file types, documents without any text, documents left checked out, or just corrupted files can cause SharePoint’s crawler to fail.
Luckily there is a way to investigate and identify crawl problems in SharePoint (although it still leaves a certain amount of guesswork necessary). The SharePoint crawler logs can show a lot of information about what was crawled, what wasn’t, errors that were encountered, and even warnings.
Administrators can investigate the crawl logs in SharePoint Central Administration in the Search service application, under the Crawler menu on the left navigation. By default the crawl log shows a list of content sources and their top-level warnings. By clicking each content source, the administrator can dig into the particular content source’s error overview. For more details on specific documents or pages, the administrator will need to choose one of the links at the top of the page to view crawl logs by hostname, URL, crawl history, or error message.
The Host Name crawler log page shows all the hostnames defined across the different content sources. Clicking individual hostnames takes the administrator to the URL page, where individual URLs are displayed with their crawl result. This can be a success, an error, or a warning. It will also show documents deleted from the crawl database.
The crawler log will report the following status messages (see Figure 1):
-
Success: The item was successfully crawled. The item has been added to the index and databases and already made searchable or the content was already in the index and has not changed.
-
Warning: A warning message indicates some issue with the crawl. This could mean that the content was crawled, not crawled, or partially crawled. A good example of this is when a file type is defined but an appropriate iFilter for that file type is not present or is not functioning properly. A warning indicates that the document and its associated metadata from SharePoint (properties) have been crawled but not the content from within the document.
-
All Errors: This message indicates there was a problem with the item and it, therefore, wasn’t crawled. If it is a new item, it will not be searchable. Old items presently in the index will not be removed until the error has been resolved and the item can be identified as deleted. The item will also not be updated.
-
Deleted: Deleted refers to all items that, for any reason, were removed from the index. These items will no longer be searchable. Items are generally deleted from an index in response to a deletion on the site or a crawl rule or a Search Result Removal.
-
Top-Level Errors: Top-level errors are a subset of the errors group and therefore are not counted in the hostname view. They are errors at the top page or entry point of the crawler that restricted it from crawling further. These errors are important as they can indicate why an entire site or content source is not indexed.
-
Folder/Site Errors: These errors are like top-level errors but represent errors only at the start page of folders or sites. Again, these errors can be useful when diagnosing errors at a lower level or on a particular site and no error for the specific item exists.
Figure 1. Filtering on status messages in the crawl logs
Crawl errors can be very difficult to decipher. SharePoint admittedly still does not have the best error logging. However, there is much that can be gleaned from the crawl logs and corrections made based on the information presented. Here are some common scenarios:
-
Warning message: “The filtering process could not load the item. This is possibly caused by an unrecognized item format or item corruption.”
This message is most likely caused by one of two problems:
-
Warning message: “This item and all items under it will not be crawled because the owner has set the NoCrawl flag to prevent it from being searchable.”
-
For non-SharePoint content, this can be caused by a Robots metatag or a robots.txt file. If the tag <META NAME=”ROBOTS” CONTENT=”NOINDEX, NOFOLLOW”> appears on the page, SharePoint will respect it and not crawl the page. If the page is listed in a robots.txt file at the root of the site, SharePoint will likewise respect this rule and not index the page.
-
Error message: “Object could not be found.”
This message indicates that when crawling a file share, the name of the file share is correct but the file to be crawled is not correct. The file will be deleted from the index. Check the file share, and make sure the content is correct and accessible by the correct user.
-
Top-level error message: “Network path for item could not be resolved.”
This message points to a problem with the file share or the resolution of a domain name. Check that the share is available or the content source is resolvable from the crawl server. Content previously crawled under this content source that is not subsequently found will not be deleted from the index.
-
Error message: “Access denied.”
“Access denied” is one of the most common error messages and indicates that the content is not accessible to the crawler. Check the permissions on the document against which user has be set as the default content access account in the Search service application.
2. Server Name Mappings
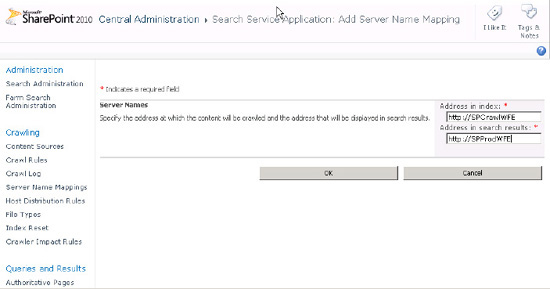
Sometimes, it is desirable to crawl one source and have the link refer to another source. For example, I have a dedicated crawl server called SPCrawlWFE, which is a mirror of my web servers that are providing content to my users. I want to crawl the SPCrawlWFE site but have the users click through to the other server (SPProdWFE). By using server name mappings, one site can be crawled and the server names on the result page links change to another server.
To add a server name mapping, navigate to the Server Name Mappings page under the Crawler section of the Search service application. Click New Mapping. On the Add New Mapping page, add the name of the site that was crawled and the name of the site users should click through to. See Figure 2.
Figure 2. Configuring server name mappings
SharePoint 2010 is going to end soon and it will no longer be supported. Learn more about how to migrate SharePoint 2010 to SharePoint Online and benefits of SharePoint Cloud Migration.

